在林子雨編著的《大數(shù)據(jù)技術(shù)原理與應(yīng)用》第八章中,作者深入探討了Hadoop作為大數(shù)據(jù)處理與存儲(chǔ)的核心平臺(tái)。Hadoop不僅是一個(gè)簡(jiǎn)單的工具,而是一個(gè)完整的生態(tài)系統(tǒng),涵蓋了數(shù)據(jù)存儲(chǔ)、處理、分析和應(yīng)用的多個(gè)層面。本章從Hadoop的基本概念出發(fā),逐步深入到其存儲(chǔ)與數(shù)據(jù)處理服務(wù)的關(guān)鍵機(jī)制。
一、Hadoop核心概念回顧
Hadoop由Apache基金會(huì)開發(fā),是一個(gè)開源的分布式計(jì)算框架,旨在處理海量數(shù)據(jù)。其核心設(shè)計(jì)理念包括分布式存儲(chǔ)(HDFS)和分布式計(jì)算(MapReduce)。HDFS提供了高容錯(cuò)性的數(shù)據(jù)存儲(chǔ),能夠?qū)⒋笪募指畛啥鄠€(gè)塊并分布在集群的節(jié)點(diǎn)上;MapReduce則是一種編程模型,用于并行處理大規(guī)模數(shù)據(jù)集。YARN(Yet Another Resource Negotiator)作為資源管理器,負(fù)責(zé)集群資源的調(diào)度與管理,使Hadoop能夠支持多種計(jì)算框架(如Spark、Flink等)。
二、數(shù)據(jù)存儲(chǔ)服務(wù):HDFS的深入解析
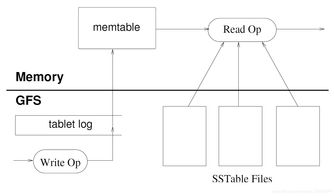
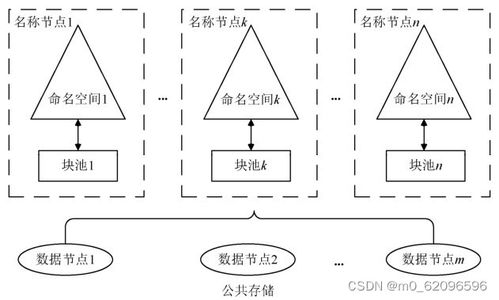
HDFS是Hadoop的存儲(chǔ)基石,其架構(gòu)包括NameNode和DataNode。NameNode作為主節(jié)點(diǎn),管理文件系統(tǒng)的元數(shù)據(jù)(如文件目錄結(jié)構(gòu)和塊位置),而DataNode作為從節(jié)點(diǎn),負(fù)責(zé)實(shí)際數(shù)據(jù)的存儲(chǔ)。HDFS通過(guò)數(shù)據(jù)冗余(默認(rèn)復(fù)制三份)確保高可用性,即使節(jié)點(diǎn)故障也能保證數(shù)據(jù)不丟失。HDFS支持流式數(shù)據(jù)訪問(wèn),適合一次寫入、多次讀取的場(chǎng)景,例如日志分析或數(shù)據(jù)倉(cāng)庫(kù)應(yīng)用。本章還探討了HDFS的優(yōu)化策略,如數(shù)據(jù)塊大小調(diào)整(默認(rèn)128MB)和機(jī)架感知策略,以減少網(wǎng)絡(luò)帶寬消耗并提升性能。
三、數(shù)據(jù)處理服務(wù):MapReduce與YARN的協(xié)同工作
MapReduce是Hadoop的數(shù)據(jù)處理引擎,其工作流程分為Map和Reduce兩個(gè)階段。在Map階段,輸入數(shù)據(jù)被分割成鍵值對(duì)并進(jìn)行初步處理;在Reduce階段,中間結(jié)果被聚合以生成最終輸出。YARN的出現(xiàn)使Hadoop從單一的MapReduce框架演變?yōu)橐粋€(gè)多任務(wù)平臺(tái),它通過(guò)ResourceManager和NodeManager管理集群資源,允許用戶運(yùn)行不同類型的應(yīng)用程序。這種分離提高了資源利用率和系統(tǒng)靈活性,使得Hadoop能夠適應(yīng)實(shí)時(shí)處理、機(jī)器學(xué)習(xí)等多樣化需求。
四、分析與應(yīng)用:Hadoop生態(tài)系統(tǒng)的擴(kuò)展
Hadoop生態(tài)系統(tǒng)不僅限于存儲(chǔ)和處理,還包括多種工具以支持?jǐn)?shù)據(jù)分析和應(yīng)用。例如,Hive提供SQL-like查詢功能,簡(jiǎn)化了大數(shù)據(jù)分析;HBase作為分布式數(shù)據(jù)庫(kù),支持實(shí)時(shí)讀寫操作;Pig則提供高級(jí)腳本語(yǔ)言,用于復(fù)雜的數(shù)據(jù)流處理。在實(shí)際應(yīng)用中,Hadoop被廣泛應(yīng)用于金融風(fēng)控、醫(yī)療數(shù)據(jù)分析、電商推薦系統(tǒng)等領(lǐng)域。通過(guò)結(jié)合這些工具,企業(yè)能夠構(gòu)建端到端的大數(shù)據(jù)解決方案,從原始數(shù)據(jù)中提取有價(jià)值的信息,驅(qū)動(dòng)業(yè)務(wù)決策和創(chuàng)新。
五、挑戰(zhàn)與未來(lái)展望
盡管Hadoop在大數(shù)據(jù)領(lǐng)域占據(jù)重要地位,但也面臨一些挑戰(zhàn),如復(fù)雜的管理、實(shí)時(shí)性不足以及安全性的提升需求。隨著云計(jì)算和邊緣計(jì)算的發(fā)展,Hadoop可能會(huì)與容器化技術(shù)(如Docker和Kubernetes)更緊密地結(jié)合,實(shí)現(xiàn)更靈活的部署。開源社區(qū)的持續(xù)創(chuàng)新將推動(dòng)Hadoop生態(tài)系統(tǒng)不斷進(jìn)化,以應(yīng)對(duì)日益增長(zhǎng)的數(shù)據(jù)處理需求。
第八章的“Hadoop再探討”強(qiáng)調(diào)了其作為數(shù)據(jù)處理和存儲(chǔ)服務(wù)的核心角色,并展示了如何通過(guò)深入理解其原理與應(yīng)用,構(gòu)建高效、可靠的大數(shù)據(jù)平臺(tái)。對(duì)于學(xué)習(xí)者和從業(yè)者而言,掌握Hadoop不僅是技術(shù)基礎(chǔ),更是解鎖大數(shù)據(jù)價(jià)值的關(guān)鍵一步。